

テキストデータの扱い方について
このページでは、さまざまなテキストデータ(文字列)をdejirenで扱う方法について説明します。
複数行の文字列から改行を除去して1行のテキストにしたいとき
処理対象の文字列を、「テキスト分割」ブロックを用いて改行で分割し、
分割した文字列を「テキスト連結」ブロックで結合しなおすことで、
改行を除去した一行の文字列とすることができます。
手順書の構成
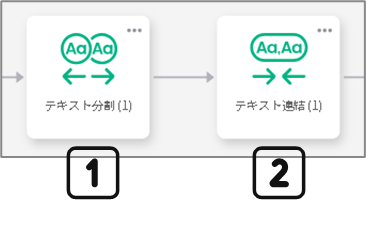
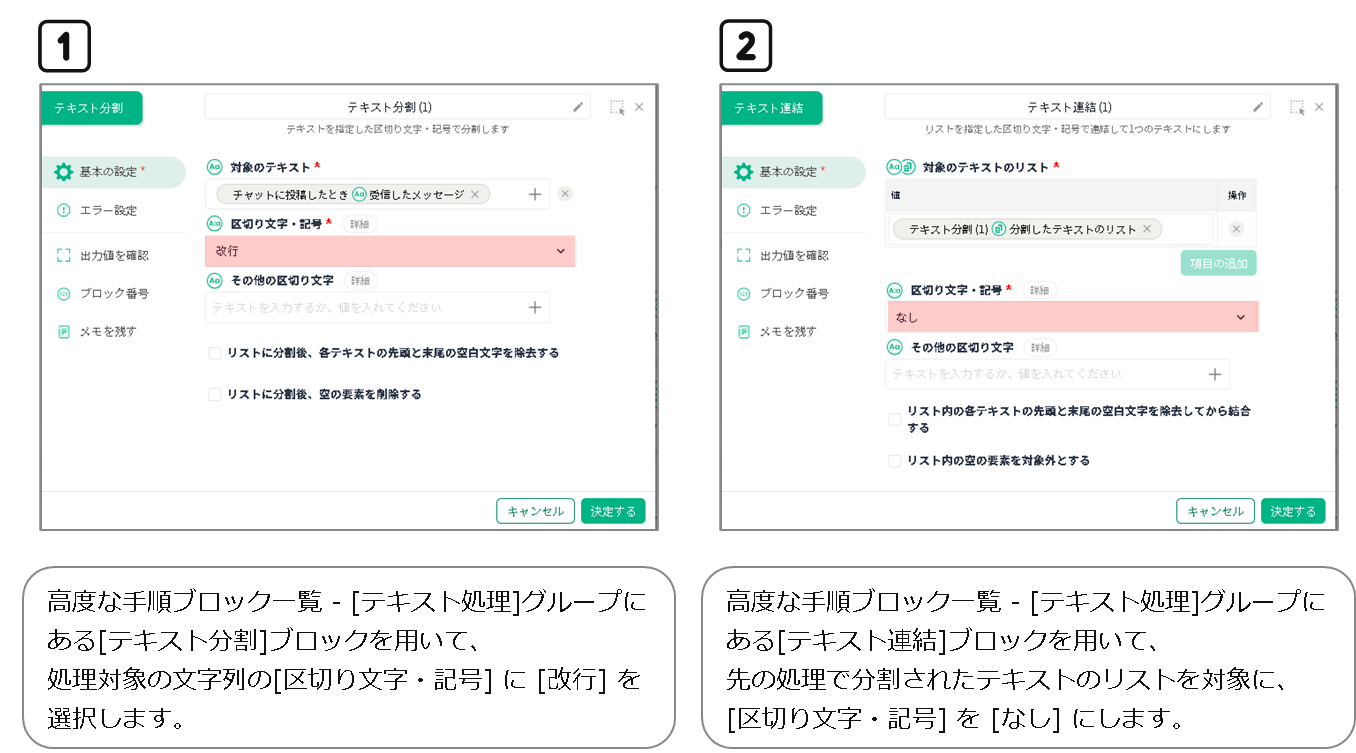
各ブロックの設定
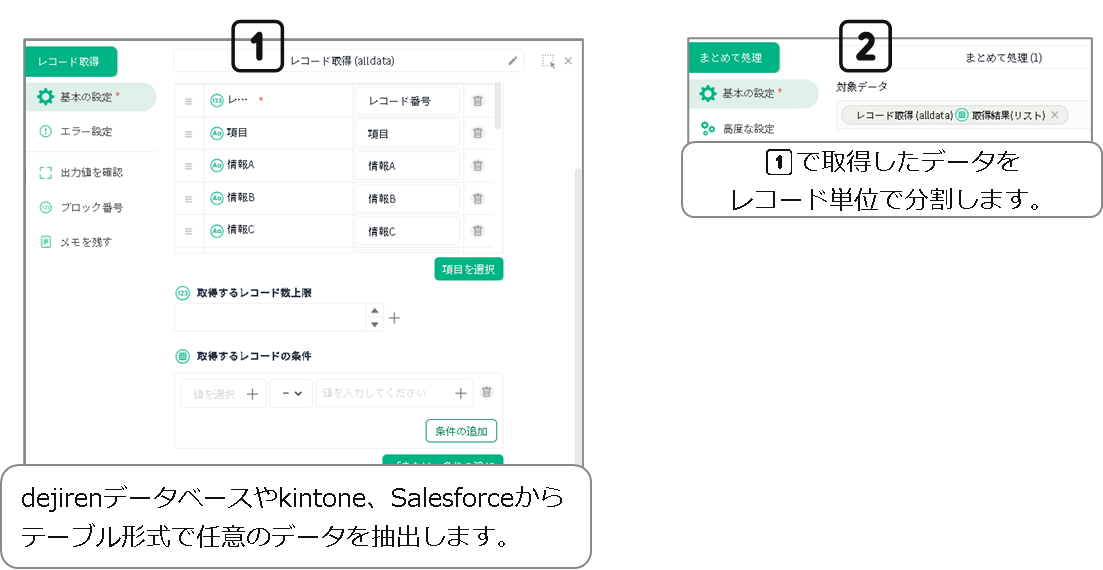
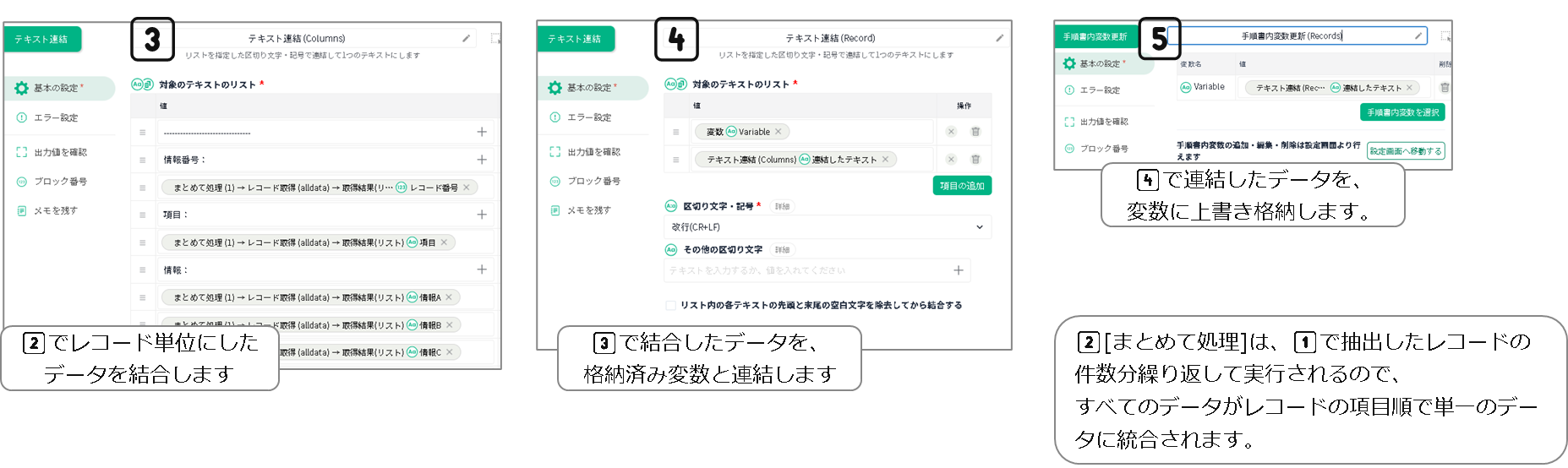
テーブルから取得した複数のデータを、情報項目単位ではなくレコード単位の文字列群に整形したいとき
dejirenデータベースなどのテーブル形式のデータ群から
データを1つずつ取り出し、手順書内変数を活用して段階的に結合します。

あらかじめデータ集約用の変数を設定しておきます。
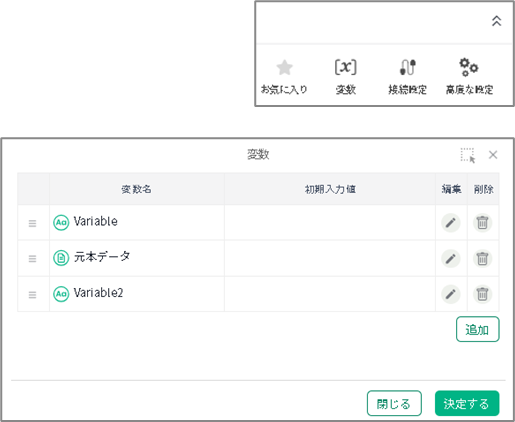
手順書の構成
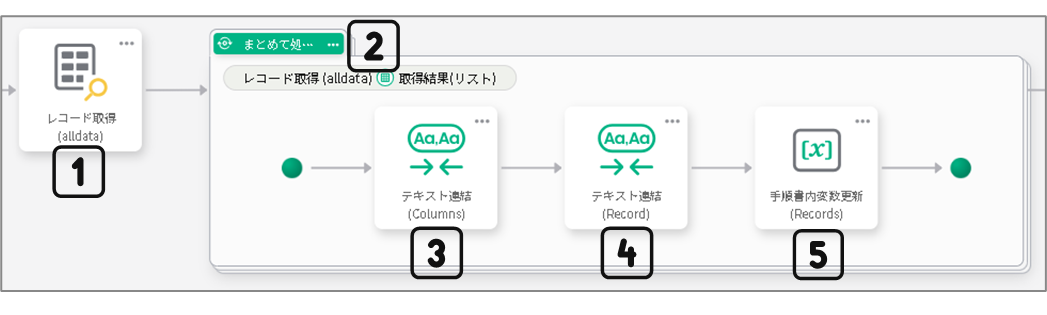
各手順ブロックの設定
文字列から特定の文言を抽出したいとき(1)/正規表現の利用
ある文字列から、指定ルールに一致する文言を抽出する「正規表現」ブロックがあります。
[高度な手順ブロック一覧] > [データ操作] > [正規表現]

正規表現用の特殊な文字(メタ文字)を組み合わせたルール(パターンと呼称)を作成し、
作成したパターンが指定した文章や文字列の中に存在するか検索します。
たとえば、次のような用途で使うことができます。
- 電話番号の正しい位置にハイフンが入力されているか。
- 全角文字が紛れ込んでいないか。
- 英数字10桁のパスワードが入力されているか。
手順書の構成
正規表現ブロックの設定項目
▼正規表現のルールを作成
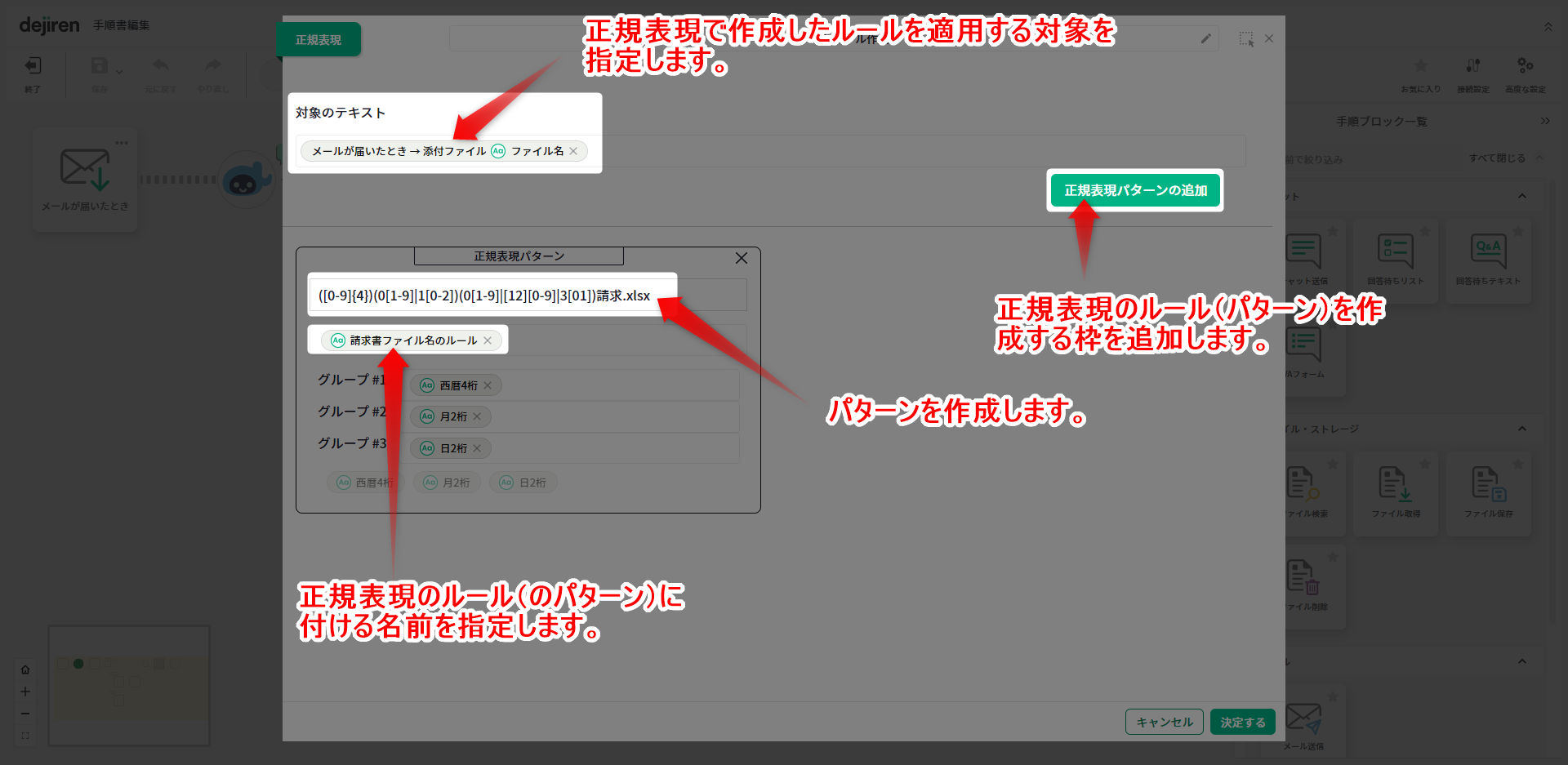
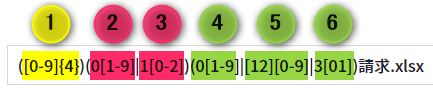
| 西暦4桁のパターン 0~9の数字が4つ連続で並んでいるか(図の黄丸1)。 月2桁のパターン 1桁目が0の場合は2桁目が1~9か(図の赤丸2)、または、 1桁目が1の場合は2桁目が0~2か(図の赤丸3)。 日2桁のパターン 1桁目が0の場合は2桁目が1~9か(図の緑丸4)、または、 1桁目が1か2の場合は2桁目が0~9か(図の緑丸5)、または、 1桁目が3の場合は2桁目が0か1か(図の緑丸6)。 ※月単位では、正しい日のチェックはしていません(2/30、4/31などは許容されます)。 |
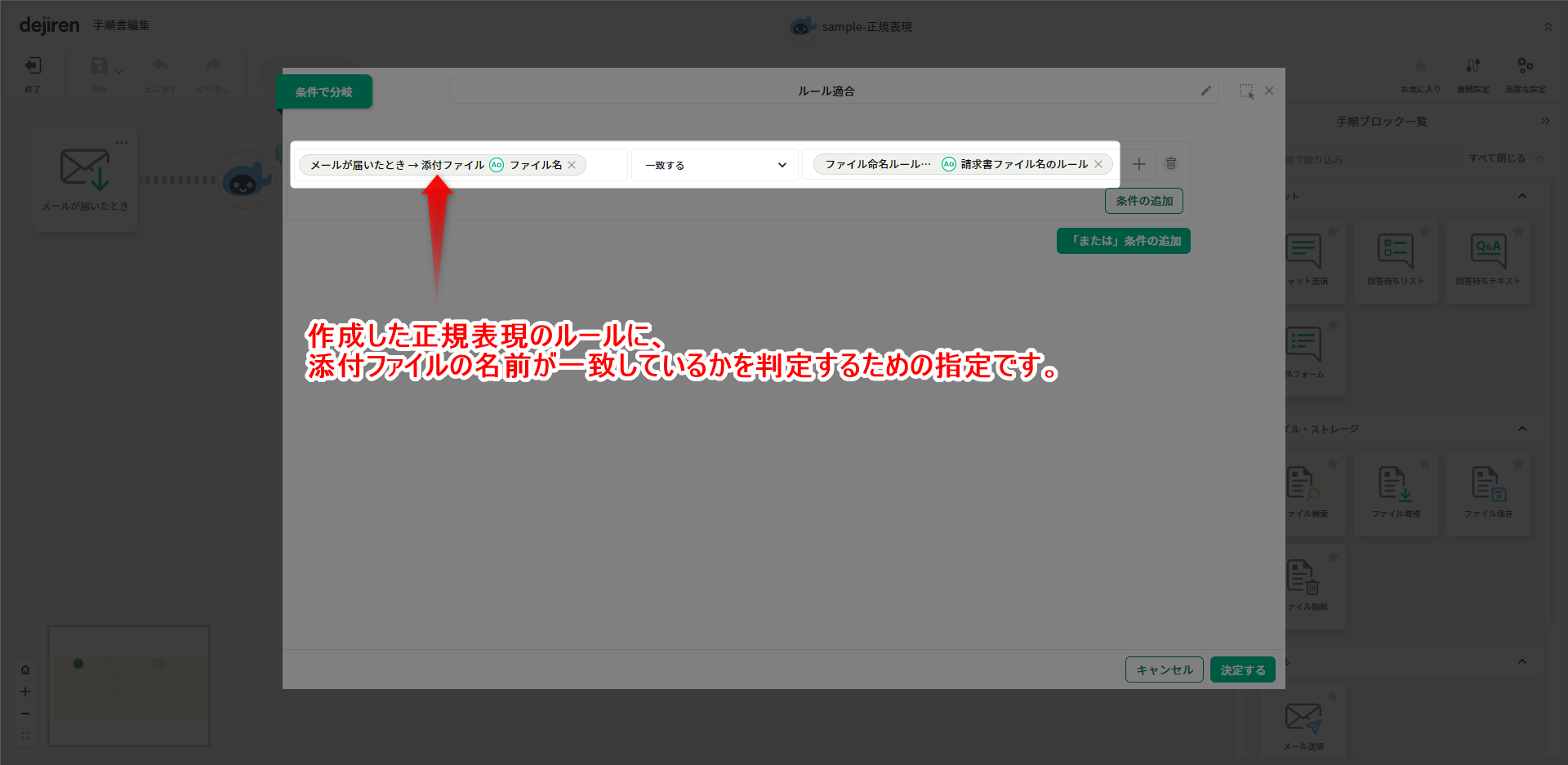
▼条件分岐の条件として、作成したパターンとファイル名とが一致するかを指定
dejirenの正規表現で、パターンに使用可能なメタ文字
| メタ文字 | 意味 | 使用例(パターン) | 一致するケース | 一致しないケース | 備考 |
|---|---|---|---|---|---|
| . | 1文字 | 私は….が好き。 | 私はコーヒーが好き。 | 私は紅茶が好き。 | コーヒーは4文字で一致、紅茶は2文字で不一致。 |
| ^ | 文頭から始まる | ^私は | 私は伺います。 | いえ、私は参りません。 | |
| $ | 文末で終わる | しました$ | お話ししました | ご案内しました、私は。 | |
| [] | いずれかの1文字と一致 | ・[春夏秋冬]が訪れます。 ・[1-5]度目のお礼です。 | ・夏が訪れます。 ・2度目のお礼です。 | ・彼が訪れます。 ・8度目のお礼です。 | 例の[1-5]内の「-」は、文字の範囲を示す特殊な文字で、この場合は「1~5のいずれか」を意味します。 |
| | | いずれかと一致 | (初春|初夏|初秋|初冬)が訪れます。 | 初夏が訪れます。 | 夏が訪れます。 | 例の()は、一致候補の語をまとめる用途で使います。これを「グループ化」といいます。 |
| ^ | 否定 | [^1-9] | b 0 | 5 | |
| * | 直前の文字を0回以上繰り返し | ab*c | abc ac abbbbbc bbbac | bbc bca | |
| + | 直前の文字を1回以上繰り返し | ab+c | abc abbbc abcccc | ac bca aacc | |
| ? | 直前の文字が0回または1回 | ab?c | abc ac | bc abbc | |
| {} | 指定文字数を繰り返し | 驚き!{3} | 驚き!!! | 驚き! |
これらを組み合わせてパターンを形成することで、メール本文やJSON文字列などから必要な箇所を切り出して後続の処理に流用することができます。
文字列から特定の文言を抽出したいとき(2)/テキスト抽出ブロック
特定の文字列から、その一部を切り出すことができる「テキスト抽出」ブロックがあります。
[高度な手順ブロック一覧] > [データ操作] > [テキスト抽出]

たとえば、次のようなときに使うことができます。
- チャットで「○○を知りたい」のような定型メッセージを受け取ると、「○○」の部分を切り出して検索条件にして、連携先のシステムから情報を取得する
- 「<日付><作成者><タイトル>.xlsx」のように規則的なファイル名から「作成者」の部分を切り出し、同じ作成者のファイルをすべて取得する
手順書の構成
テキスト抽出ブロックの項目設定
▼設定例
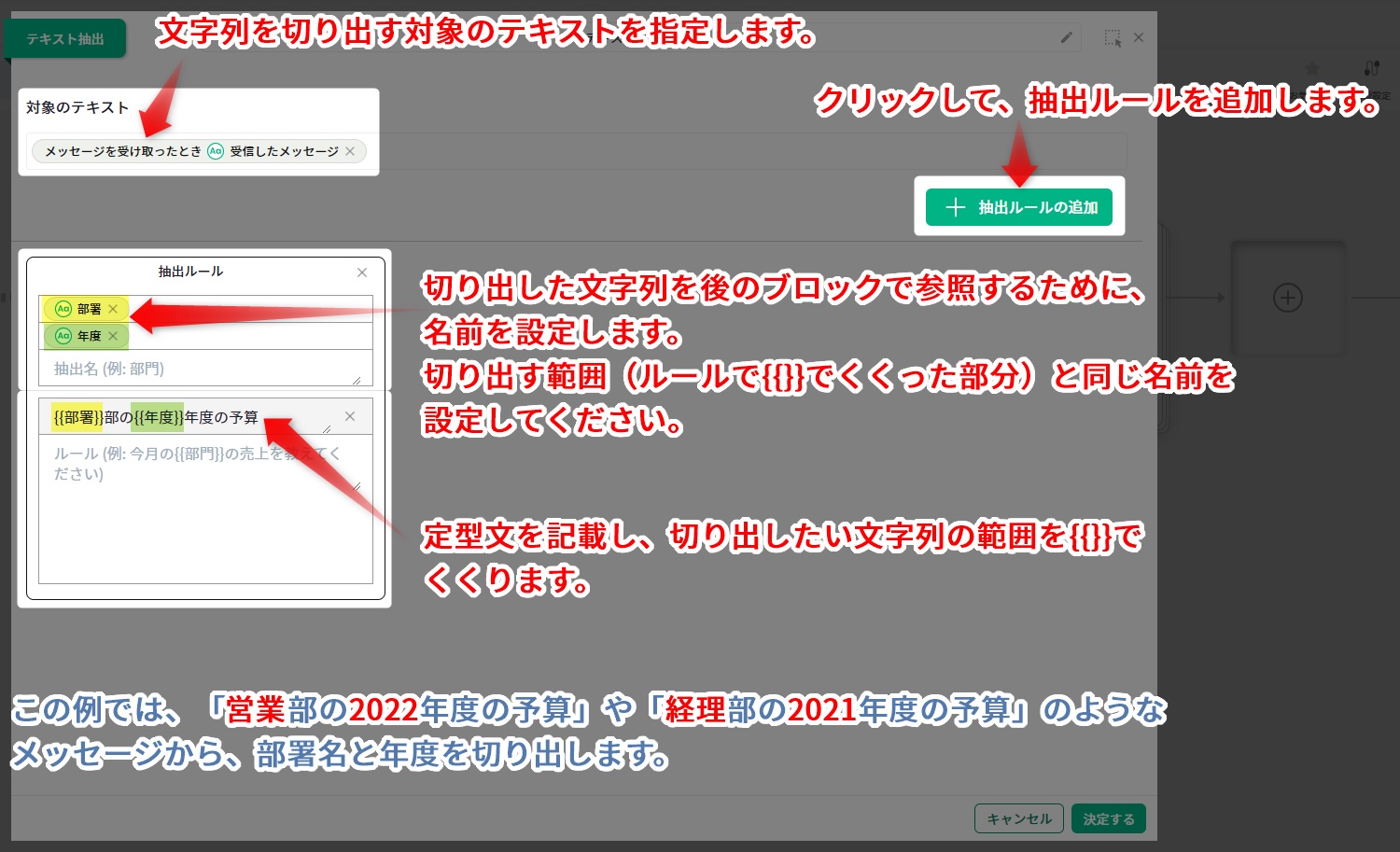
テキスト抽出ブロックで切り出した値を、後続のブロックの処理に用いることが出来ます。
テキスト抽出の留意点
- [抽出名]と[抽出ルール]の {{}} 内の名前が異なると、文字列を切り出せません。
- テキストの一部(または全体)が設定したルールに完全に一致する場合のみ、文字列を切り出せます。
したがって、上記の例では「営業部の2022年度の予算」や「営業部の2022年度の予算を知りたい」から「営業」と「2022」を切り出せますが、
「2022年度の営業部の予算を知りたい」からは切り出せません。 - 抽出ルールを追加することで、「2022年度の営業部の予算を知りたい」のように語順が変わる表現からも文字列を切り出すことが可能です。
文字列・文章に特定の文言が含まれるか検索したいとき/テキスト分析ブロック
文字列・文章に、特定のキーワードが含まれているかを調べたいときには、
「テキスト分析」ブロックを使います。
[高度な手順ブロック一覧] > [データ操作] > [テキスト分析]

たとえば、次のような使い方ができます。
- 受信したメールの件名にキーワードが含まれていたら、チャットで通知する
- チャットの添付ファイル名にキーワードが含まれていたら、特定のフォルダーにアップロードする
- チャットのメッセージにキーワードが含まれていたら、VAの動作を変える
手順書の構成
テキスト分析ブロックの設定
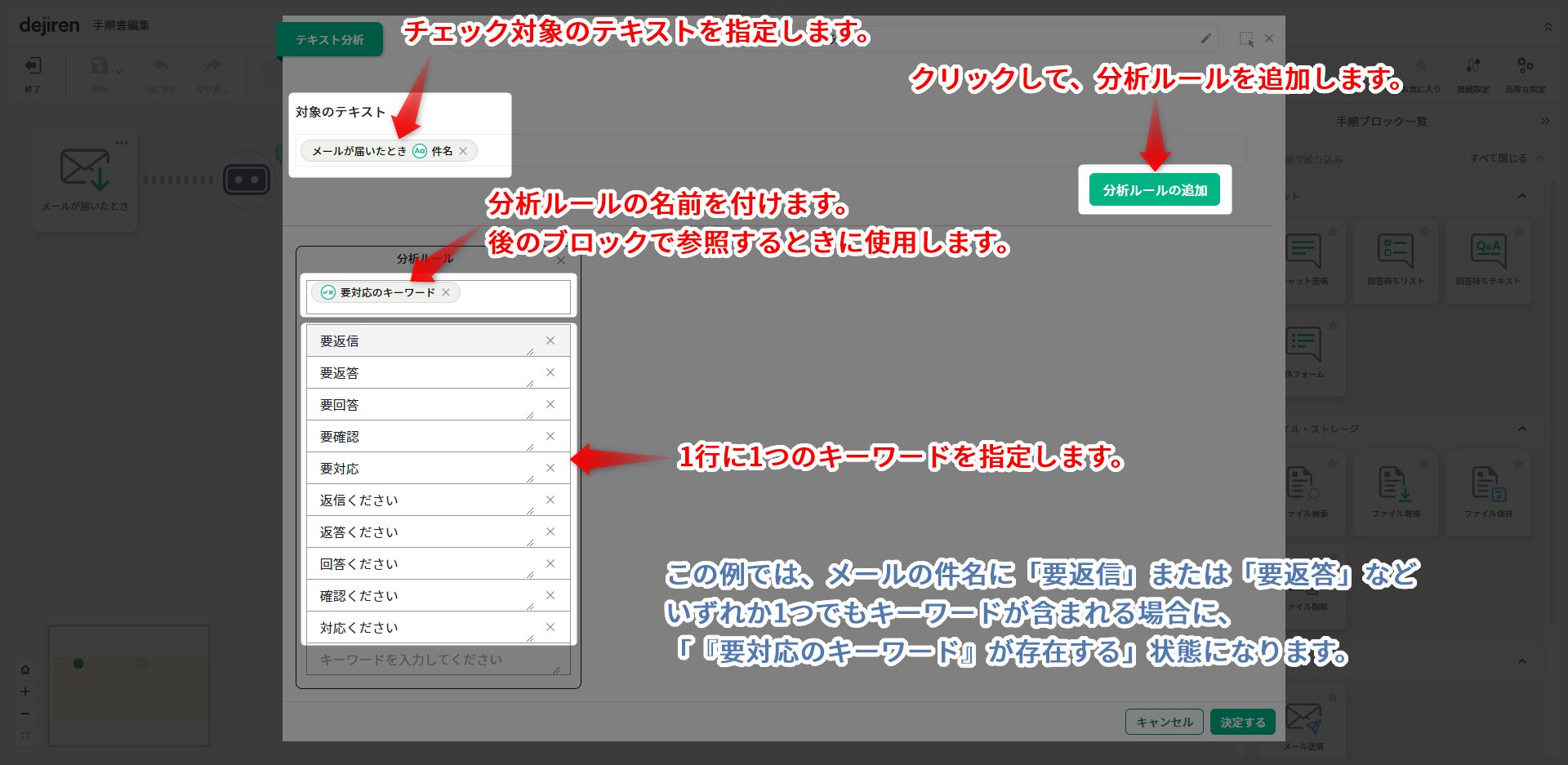
文字列を分析して、該当する情報が含まれていた場合、後続の処理をどうするのか[条件分岐](「値で分岐」)などで処理を変動させることが出来ます。
テキスト分析の留意点
- 分析ルールとは、キーワードのバリエーションをまとめたものです。
このブロックの後に「条件で分岐」ブロックを配置するとき、
分岐条件には、分析ルールの名前を[存在する]で判定します。
[一致する]や[含む]ではないため、注意してください。 - 「条件で分岐」ブロックだけでも、テキストにキーワードが含まれるか調べられます。
ただし、調べたいキーワードの数が多い場合は次のような問題があるため、
「テキスト分析」ブロックの使用をご検討ください。
1. キーワードごとに、対象となるテキストや条件を選択しなければならない。
2. [または]条件が多くなり、キーワードの見通しが悪くなる。
3. キーワードだけでなく、他の条件(たとえば、「特定の人から送信されたメール」など)もある場合に、条件分岐の階層が深く、複雑になる。
#文字列結合 #文字列連結 #コンバイン #テーブル #正規表現 #メタ文字 #抽出 #切り出 #切出 #抜出 #抜き出 #取り出 #取出 #要素 #一部 #dejirenデータベース #Salesforce #kintone #RegEx #”regular expression” #extract #”cut out” #cutout





